

概率公式总结大全(常见的8个概率分布公式和可视化)
概率公式总结大全(常见的8个概率分布公式和可视化)
概率和统计知识是数据科学和机器学习的核心; 我们需要统计和概率知识来有效地收集、审查、分析数据。
现实世界中有几个现象实例被认为是统计性质的(即天气数据、销售数据、财务数据等)。 这意味着在某些情况下,我们已经能够开发出方法来帮助我们通过可以描述数据特征的数学函数来模拟自然。
“概率分布是一个数学函数,它给出了实验中不同可能结果的发生概率。”
了解数据的分布有助于更好地模拟我们周围的世界。 它可以帮助我们确定各种结果的可能性,或估计事件的可变性。 所有这些都使得了解不同的概率分布在数据科学和机器学习中非常有价值。

在本文中,我们将介绍一些常见的分布并通过Python 代码进行可视化以直观地显示它们。
均匀分布
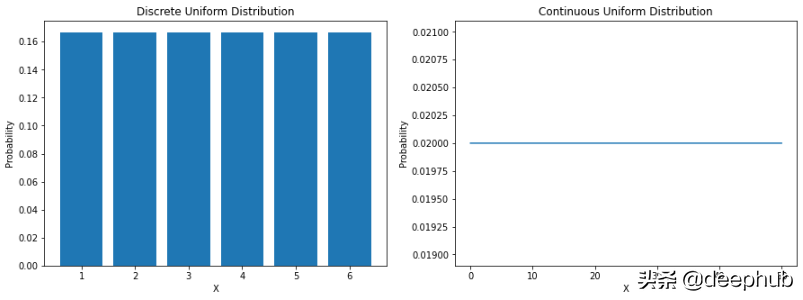
最直接的分布是均匀分布。 均匀分布是一种概率分布,其中所有结果的可能性均等。 例如,如果我们掷一个公平的骰子,落在任何数字上的概率是 1/6。 这是一个离散的均匀分布。
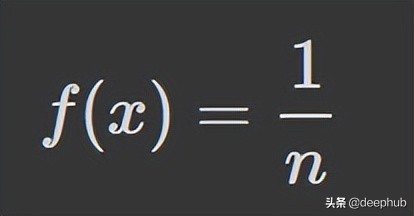
但是并不是所有的均匀分布都是离散的——它们也可以是连续的。 它们可以在指定范围内取任何实际值。 a 和 b 之间连续均匀分布的概率密度函数 (PDF) 如下:
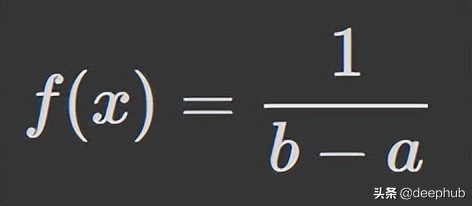
让我们看看如何在 Python 中对它们进行编码:
importnumpyasnp importmatplotlib.pyplotasplt fromscipyimportstats#forcontinuousa=0 b=50 size=5000 X_continuous=np.linspace(a,b,size) continuous_uniform=stats.uniform(loc=a,scale=b) continuous_uniform_pdf=continuous_uniform.pdf(X_continuous)#fordiscreteX_discrete=np.arange(1,7) discrete_uniform=stats.randint(1,7) discrete_uniform_pmf=discrete_uniform.pmf(X_discrete)#plotbothtablesfig,ax=plt.subplots(nrows=1,ncols=2,figsize=(15,5))#discreteplotax[0].bar(X_discrete,discrete_uniform_pmf) ax[0].set_xlabel("X") ax[0].set_ylabel("Probability") ax[0].set_title("DiscreteUniformDistribution")#continuousplotax[1].plot(X_continuous,continuous_uniform_pdf) ax[1].set_xlabel("X") ax[1].set_ylabel("Probability") ax[1].set_title("ContinuousUniformDistribution") plt.show()
高斯分布
高斯分布可能是最常听到也熟悉的分布。 它有几个名字:有人称它为钟形曲线,因为它的概率图看起来像一个钟形,有人称它为高斯分布,因为首先描述它的德国数学家卡尔·高斯命名,还有一些人称它为正态分布,因为早期的统计学家 注意到它一遍又一遍地再次发生。
正态分布的概率密度函数如下:
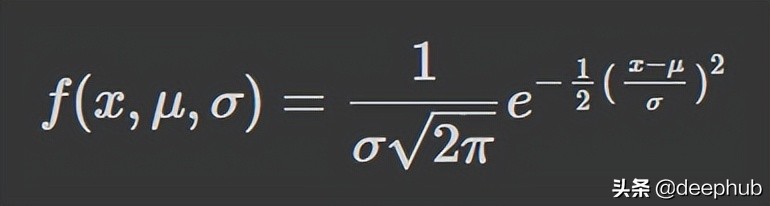
σ 是标准偏差,μ 是分布的平均值。 要注意的是,在正态分布中,均值、众数和中位数都是相等的。
当我们绘制正态分布的随机变量时,曲线围绕均值对称——一半的值在中心的左侧,一半在中心的右侧。 并且,曲线下的总面积为 1。
mu=0variance=1sigma=np.sqrt(variance)x=np.linspace(mu-3*sigma,mu+3*sigma,100)plt.subplots(figsize=(8,5))plt.plot(x,stats.norm.pdf(x,mu,sigma))plt.title("NormalDistribution")plt.show()
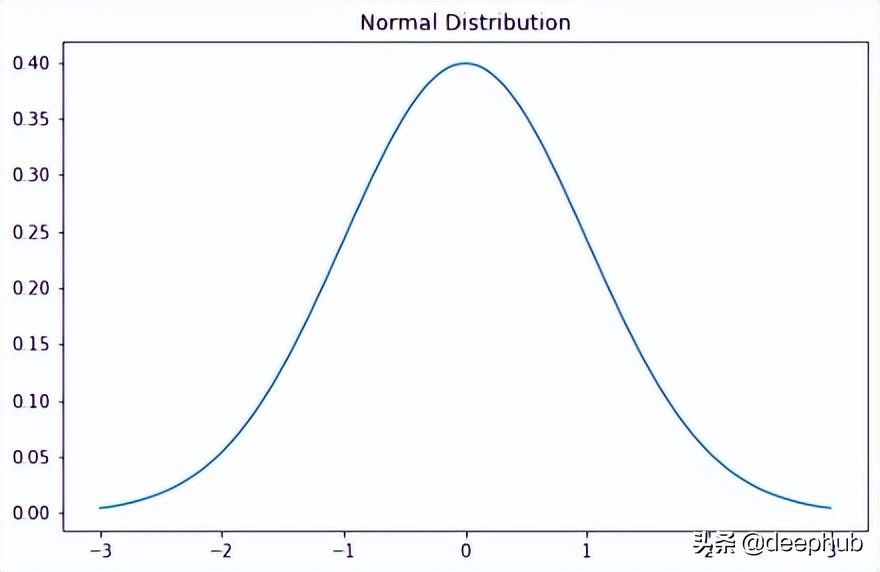
对于正态分布来说。 经验规则告诉我们数据的百分比落在平均值的一定数量的标准偏差内。 这些百分比是:
68% 的数据落在平均值的一个标准差内。
95% 的数据落在平均值的两个标准差内。
99.7% 的数据落在平均值的三个标准差范围内。
对数正态分布
对数正态分布是对数呈正态分布的随机变量的连续概率分布。 因此,如果随机变量 X 是对数正态分布的,则 Y = ln(X) 具有正态分布。
这是对数正态分布的 PDF:
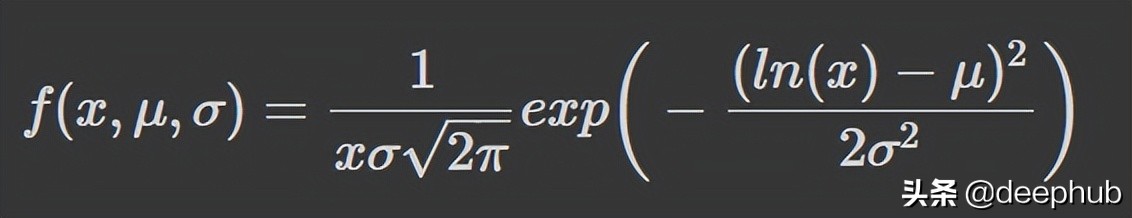
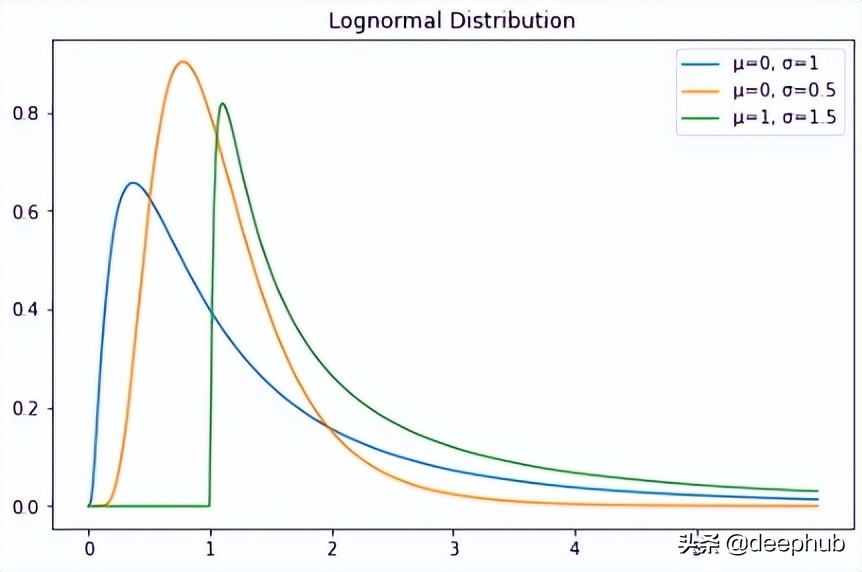
对数正态分布的随机变量只取正实数值。 因此,对数正态分布会创建右偏曲线。
让我们在 Python 中绘制它:
X=np.linspace(0,6,500) std=1 mean=0 lognorm_distribution=stats.lognorm([std],loc=mean) lognorm_distribution_pdf=lognorm_distribution.pdf(X) fig,ax=plt.subplots(figsize=(8,5)) plt.plot(X,lognorm_distribution_pdf,label="μ=0,σ=1") ax.set_xticks(np.arange(min(X),max(X))) std=0.5 mean=0 lognorm_distribution=stats.lognorm([std],loc=mean) lognorm_distribution_pdf=lognorm_distribution.pdf(X) plt.plot(X,lognorm_distribution_pdf,label="μ=0,σ=0.5") std=1.5 mean=1 lognorm_distribution=stats.lognorm([std],loc=mean) lognorm_distribution_pdf=lognorm_distribution.pdf(X) plt.plot(X,lognorm_distribution_pdf,label="μ=1,σ=1.5") plt.title("LognormalDistribution") plt.legend() plt.show()
泊松分布
泊松分布以法国数学家西蒙·丹尼斯·泊松的名字命名。 这是一个离散的概率分布,这意味着它计算具有有限结果的事件——换句话说,它是一个计数分布。 因此,泊松分布用于显示事件在指定时期内可能发生的次数。
如果一个事件在时间上以固定的速率发生,那么及时观察到事件的数量(n)的概率可以用泊松分布来描述。 例如,顾客可能以每分钟 3 次的平均速度到达咖啡馆。 我们可以使用泊松分布来计算 9 个客户在 2 分钟内到达的概率。
下面是概率质量函数公式:
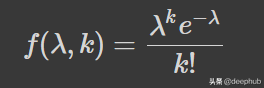
λ 是一个时间单位的事件率——在我们的例子中,它是 3。k 是出现的次数——在我们的例子中,它是 9。这里可以使用 Scipy 来完成概率的计算。
fromscipyimportstats print(stats.poisson.pmf(k=9,mu=3))""" 0.002700503931560479 """
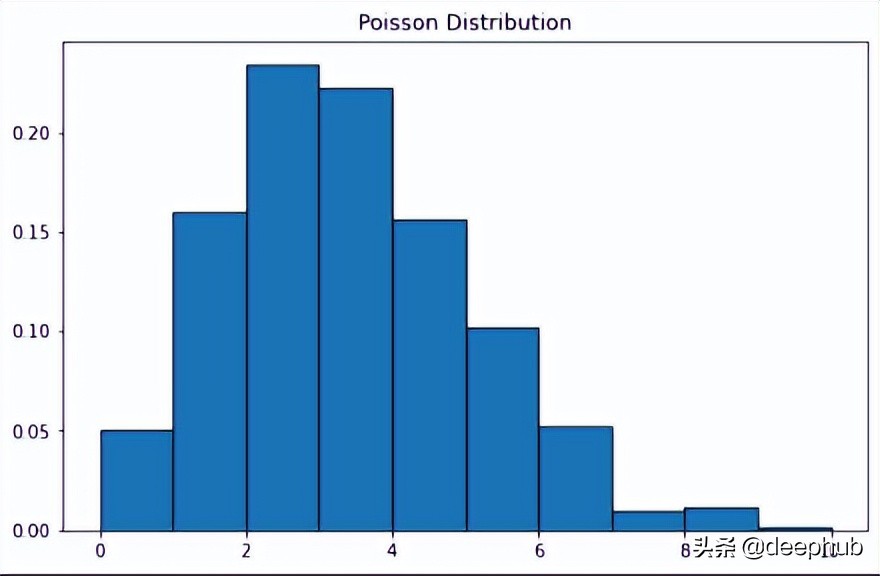
泊松分布的曲线类似于正态分布,λ 表示峰值。
X=stats.poisson.rvs(mu=3,size=500) plt.subplots(figsize=(8,5)) plt.hist(X,density=True,edgecolor="black") plt.title("PoissonDistribution") plt.show()
指数分布
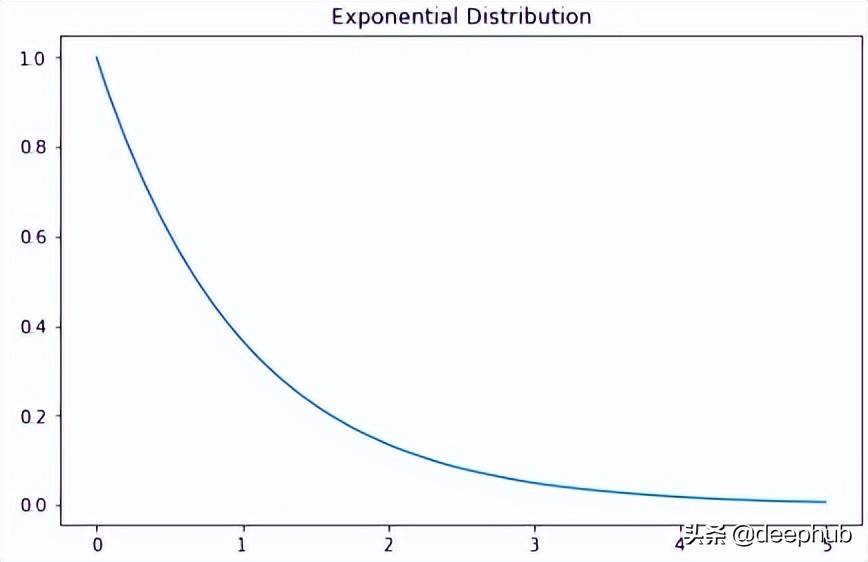
指数分布是泊松点过程中事件之间时间的概率分布。指数分布的概率密度函数如下:
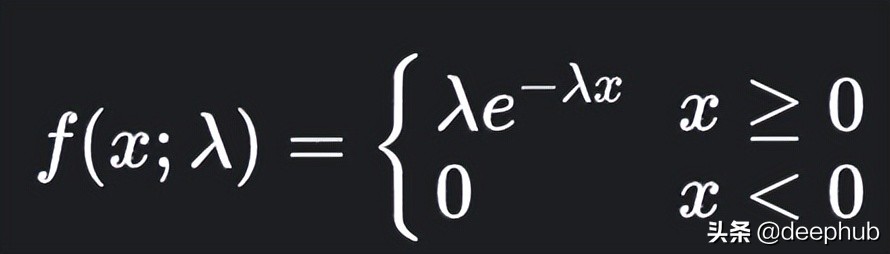
λ 是速率参数,x 是随机变量。
X=np.linspace(0,5,5000) exponetial_distribtuion=stats.expon.pdf(X,loc=0,scale=1) plt.subplots(figsize=(8,5)) plt.plot(X,exponetial_distribtuion) plt.title("ExponentialDistribution") plt.show()
二项分布
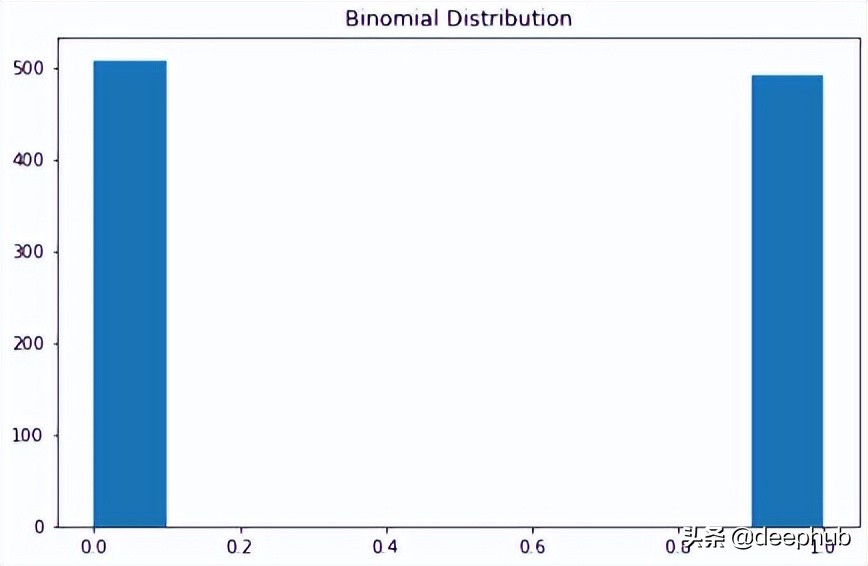
可以将二项分布视为实验中成功或失败的概率。 有些人也可能将其描述为抛硬币概率。
参数为 n 和 p 的二项式分布是在 n 个独立实验序列中成功次数的离散概率分布,每个实验都问一个是 – 否问题,每个实验都有自己的布尔值结果:成功或失败。
本质上,二项分布测量两个事件的概率。 一个事件发生的概率为 p,另一事件发生的概率为 1-p。
这是二项分布的公式:

可视化代码如下:
X=np.random.binomial(n=1,p=0.5,size=1000) plt.subplots(figsize=(8,5)) plt.hist(X) plt.title("BinomialDistribution") plt.show()
学生 t 分布
学生 t 分布(或简称 t 分布)是在样本量较小且总体标准差未知的情况下估计正态分布总体的均值时出现的连续概率分布族的任何成员。 它是由英国统计学家威廉·西利·戈塞特(William Sealy Gosset)以笔名“student”开发的。
PDF如下:
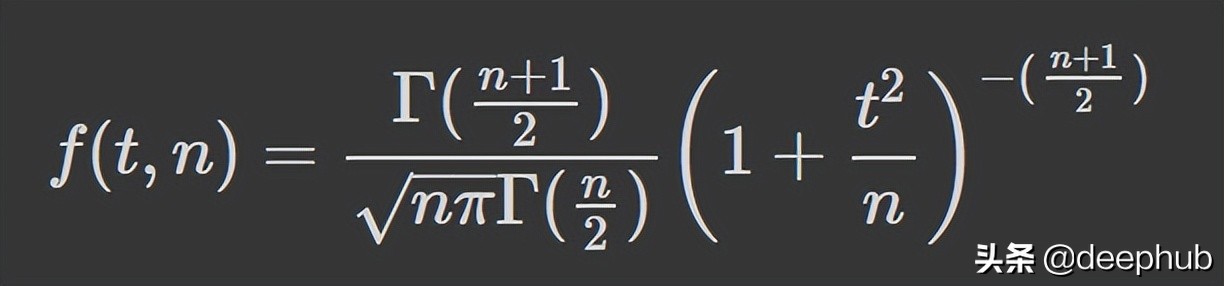
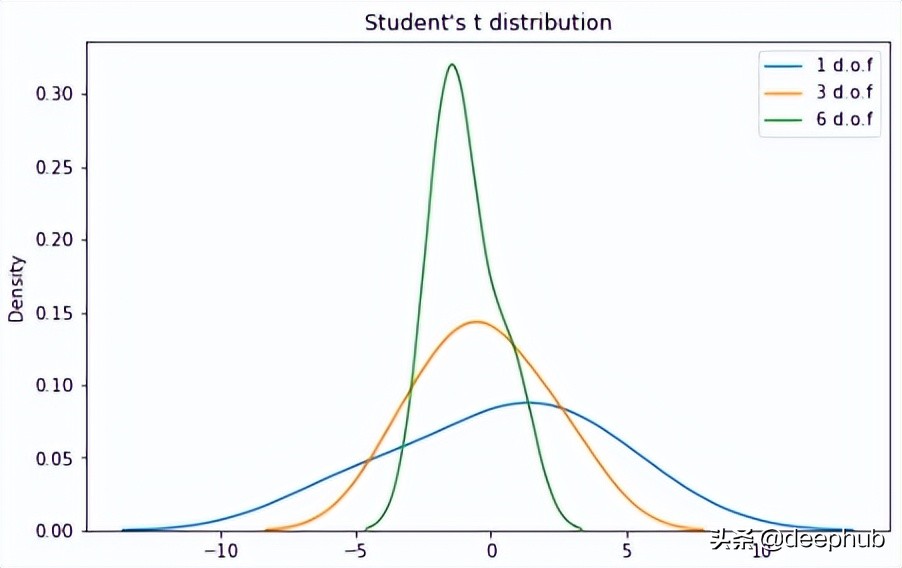
n 是称为“自由度”的参数,有时可以看到它被称为“d.o.f.” 对于较高的 n 值,t 分布更接近正态分布。
importseabornassnsfromscipyimportstats X1=stats.t.rvs(df=1,size=4) X2=stats.t.rvs(df=3,size=4) X3=stats.t.rvs(df=9,size=4) plt.subplots(figsize=(8,5)) sns.kdeplot(X1,label="1d.o.f") sns.kdeplot(X2,label="3d.o.f") sns.kdeplot(X3,label="6d.o.f") plt.title("Student'stdistribution") plt.legend() plt.show()
卡方分布
卡方分布是伽马分布的一个特例; 对于 k 个自由度,卡方分布是一些独立的标准正态随机变量的 k 的平方和。
PDF如下:
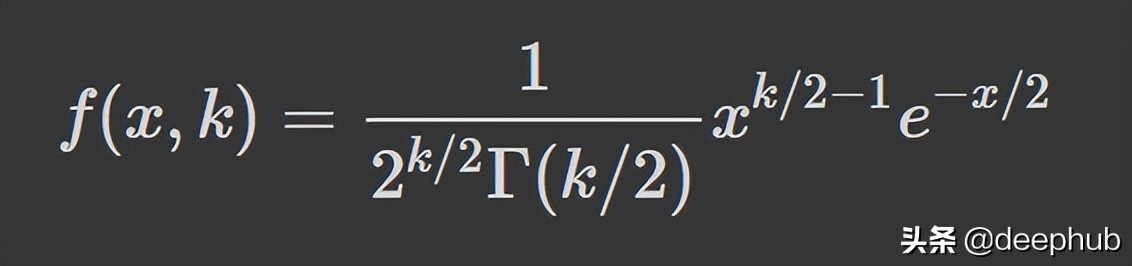
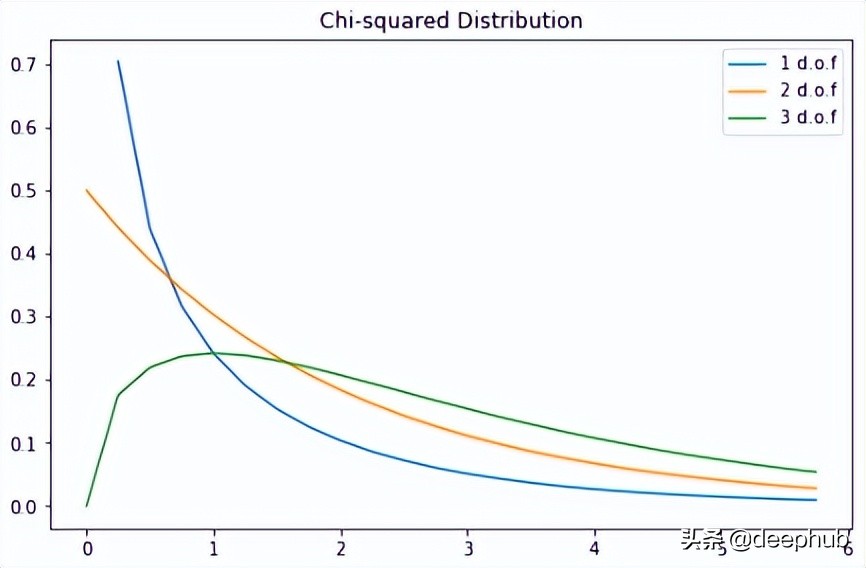
这是一种流行的概率分布,常用于假设检验和置信区间的构建。
让我们在 Python 中绘制一些示例图:
X=np.arange(0,6,0.25) plt.subplots(figsize=(8,5)) plt.plot(X,stats.chi2.pdf(X,df=1),label="1d.o.f") plt.plot(X,stats.chi2.pdf(X,df=2),label="2d.o.f") plt.plot(X,stats.chi2.pdf(X,df=3),label="3d.o.f") plt.title("Chi-squaredDistribution") plt.legend() plt.show()
掌握统计学和概率对于数据科学至关重要。 在本文展示了一些常见且常用的分布,希望对你有所帮助。
-

- 冬天身上烟味大怎么去掉,怎样有效去除身上的烟味
-
2025-11-06 17:39:43
-

- 杜甫的三吏三别中三吏是哪三个?三别又是哪三个?
-
2025-11-06 17:37:28
-

- 农历鬼月是几月?有什么讲究有哪些禁忌一定要注意?
-
2025-11-06 17:35:13
-

- 努洛伊曼皇宫(努洛伊曼皇宫造价)
-
2025-11-06 14:07:12
-

- 稻花香白酒42度黄金宴6 稻花香知行42度白酒
-
2025-11-06 14:04:57
-

- 电脑硬件分享教程(有哪些电脑硬件圈子里才知道的小秘密)
-
2025-11-06 14:02:42
-

- 命不久矣(命不久矣的体质快穿)
-
2025-11-06 14:00:27
-

- 防冻措施有哪些,防止霜冻的措施有哪些?
-
2025-11-06 13:58:12
-

- 冬天的哈尔滨雪景(飘雪的哈尔滨美翻了)
-
2025-11-06 12:45:25
-

- “绮”怎么读?
-
2025-11-06 04:04:22
-

- “偶尔”的常用英语表达
-
2025-11-06 04:02:07
-

- “塔西佗陷阱”是什么?丨舆论知识点
-
2025-11-06 03:59:52
-
- “世界最性感建筑”之一,这座大桥就像迷宫,不小心就会走丢
-
2025-11-06 03:57:38
-
- “开学”英文怎么说?可不是“Open school”
-
2025-11-06 03:55:23
-

- “好奇号”续探火星盖尔陨石坑 传回表面布满岩石的瑰丽景象
-
2025-11-06 03:53:08
-

- “令人想入非非”的4张照片,纲手大蛇丸不算啥,卡卡西的才惊艳
-
2025-11-06 03:50:53
-

- “丘辟特之家”:意大利庞贝古城大宅发现2000年历史壁画装饰
-
2025-11-06 03:48:38
-
- “火星快车”号空间轨道探测器飞越火星北极“雪湖”科罗廖夫火山口的视频
-
2025-11-06 03:46:23
-

- “鸟中哈士奇”鲸头鹳能吃小鳄鱼 看见人类会鞠躬敬礼
-
2025-11-06 03:44:08
-

- 露营应该选在什么地方
-
2025-11-06 01:44:49
 从人均985到遍地键盘侠,我在WP7吧看到了互联网的悲哀
从人均985到遍地键盘侠,我在WP7吧看到了互联网的悲哀 吴亦凡被全网封杀,妈妈吴秀芹上线几十次,网友说她做对一件好事
吴亦凡被全网封杀,妈妈吴秀芹上线几十次,网友说她做对一件好事 受贿1787万余元!联通资产运营有限公司原副总张清贵一审获刑11年半
受贿1787万余元!联通资产运营有限公司原副总张清贵一审获刑11年半 卡尔维诺:一位因口头表达能力差而走上写作道路的“苦行派”作家
卡尔维诺:一位因口头表达能力差而走上写作道路的“苦行派”作家 河南银保监局打出政策组合拳 全力支持稳住经济大盘
河南银保监局打出政策组合拳 全力支持稳住经济大盘 开天眼后到底能看到什么?震惊了千万人!不可思议!
开天眼后到底能看到什么?震惊了千万人!不可思议! 除了小龙虾,五一档竟然还有哲学与诗?
除了小龙虾,五一档竟然还有哲学与诗? 河北名山,爬山好去处,你去过几座?第一篇
河北名山,爬山好去处,你去过几座?第一篇 黄荣奇和史鸿飞,风格完全相反,却凸显出国内球员的一大问题
黄荣奇和史鸿飞,风格完全相反,却凸显出国内球员的一大问题